At peak, this means about 3,000 inbound availability searches per second — roughly 100 million a day. However, one inbound search rarely translates to one upstream call depending on the location, we figure out which suppliers can serve it and fan out to anywhere from 10 to 40 different supplier APIs. Some suppliers will return a price in a single call; others want us to authenticate, fetch the fleet, pull rate rules, and then ask for availability. Supplier integrations are by far the most resource-hungry thing we do.
For roughly six years, we ran each supplier as its own Node.js service. In 2023, we started collapsing them into SupplierHub, a modular monolith written in Go. Migration is underway, starting where the impact is greatest.
This article is about why we made that change, what we got wrong along the way, and the broader lesson we keep coming back to.
How we got here
CRG started as a PHP monolith. By around 2017, the supplier-integration story was getting messy. Every supplier API has its own shape: different auth flows, different rate-rule semantics, different ways of expressing fleet availability, and orchestrating that inside the PHP codebase was getting harder every quarter. Supplier integrations were the natural first thing to extract.
We picked Node.js with Restify, later moving to Fastify when Restify went unmaintained. Supplier work is overwhelmingly I/O-bound: wait for the upstream, parse the response, normalise it. Node fit that shape well. Go was on the table, but in 2017 we didn’t have in-house Go expertise, and the ecosystem felt less settled. It was a pragmatic call at the time.
Our design then was simple: define a common interface for supplier capabilities, then implement it once per supplier. Each implementation became its own service. The PHP monolith shrank into an orchestration layer, while the supplier-specific weirdness lived inside the supplier services.
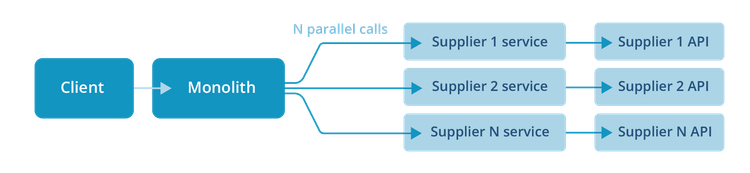
This worked for years.
What broke
The number of services kept growing. Every new supplier was a new service, and we kept onboarding new suppliers. Once we got past about 50, the failure modes started to change.
Maintenance became the job. Each Node.js LTS line is supported for roughly 30 months end-to-end, but only the first 18 months are active support. Multiply that across 50+ services, and there is always a runtime upgrade somewhere on the roadmap. Then come dependency updates, security patches, and the occasional breaking change in a shared library. Want to add a new field to the availability response? A new auth-refresh strategy? Suddenly it is a 50-PR rollout, and the inevitable inconsistencies — three suppliers on one version of a helper, the rest on another — cost more than the change itself.
Boilerplate compounded. New-supplier setup was overwhelmingly the same boilerplate as the existing services. We tried scaffolding templates, but it was hard to keep the template current and harder still to enforce its use. The path of least resistance was always to copy the most recent service and tweak it, so drift became inevitable.
The cost-shape was wrong. Supplier traffic has a long tail: a handful of suppliers account for the bulk of the volume, while most are quiet. But every service still needed at least two instances running for high availability. We were paying for redundancy on services that handled only a few requests a minute.
The thing is, the original service-per-supplier design was solving real problems: independent deploys, blast-radius isolation, and per-service scaling. Those are not nothing. But in practice, after a few years, almost every supplier integration looked like every other one operationally. They had different code, but nearly identical runtime needs. We were paying microservice-shaped costs for monolith-shaped workloads.
The reframe
The interesting question turned out not to be ‘monolith or microservices?’ That is the internet argument, and the wrong one. The real question was: what does the supplier-integration boundary actually need to give us?
We landed on two answers:
1. A clean, stable interface. Each supplier should be a black box that implements a known contract: availability, booking, modify, cancellation. The rest of the system shouldn’t care how each one is wired up internally.
2. The option of independent deployment, not the obligation. A handful of suppliers really do need to be isolated for regulatory reasons, traffic spikes, or weird upstream behaviour. The rest don’t.
The first answer is about code structure. The second is about deployment topology. Service-per-supplier conflated the two. A modular monolith does not have to.
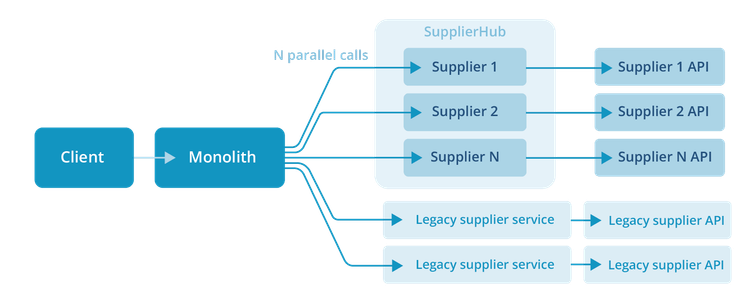
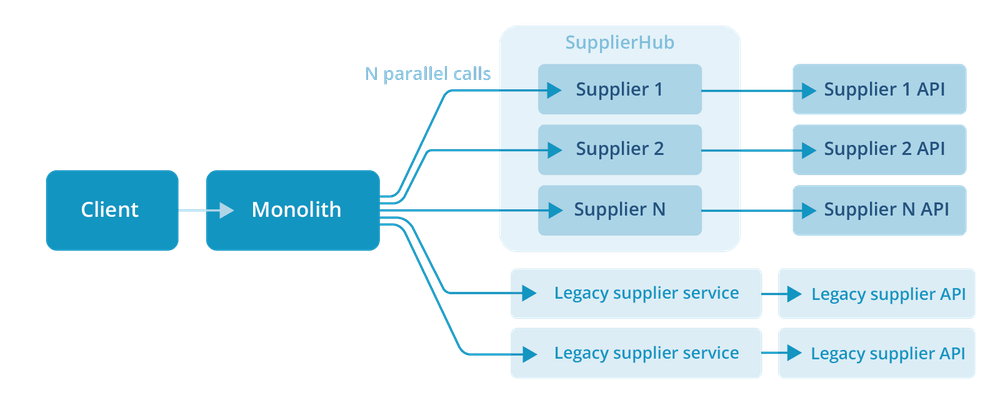
SupplierHub
In 2023, we started building SupplierHub: a single Go service in which each supplier integration is an isolated package implementing whichever interfaces it supports. The orchestration layer talks to SupplierHub the same way it used to talk to the individual services.
Each supplier is a Go package that implements the interfaces it actually supports. Some suppliers do availability and booking but not modifications; others do the full set. The interface set declares the contract; the package decides what it can fulfil.
The escape hatch matters too: if a supplier needs its own deployment for any reason, such as traffic profile, isolation or debugging, we ship the same binary, configured to expose only that supplier. Same code, different deployment. We do not need it often, but it is there when we do.
What we got wrong
Two years in, the migration is going well, but we have made our share of mistakes. Two are worth sharing.
HTTP client defaults are not your defaults. Go's (net/http) client ships with sensible defaults for the median case: keepalive on, HTTP/2 negotiation enabled, and connection pooling tuned for general use. Supplier APIs are not the median case. Some of them mishandle keepalive connections such as servers that close idle sockets aggressively, or load balancers that break sticky sessions in ways that surface as random TLS errors. Others are misconfigured for HTTP/2 in ways that produce mysterious latency cliffs. We learned this the hard way: by shipping SupplierHub with the defaults, then chasing tail-latency spikes that turned out to be the client and the supplier disagreeing about connection reuse.
The fix was not a single setting; it was per-supplier tuning. For some suppliers, turning keepalive off cut 99th percentile latency dramatically. For others, keeping keepalive on was substantially more performant. There is no universally correct answer; you have to measure each upstream. We now treat HTTP client configuration as part of the supplier-package contract, not as a global default.
We pre-optimised without profiling. Early on, we made a handful of ‘this will be hot, so let’s write it carefully’ decisions in the availability path: object pooling, hand-rolled parsing, and some allocation-avoidance gymnastics. When we eventually profiled under realistic load, almost none of them were the actual hotspots. The real hotspots were elsewhere, in code we had not thought to inspect. Meanwhile, the careful code we had written added complexity without moving the needle.
What we changed: every new supplier with an availability or rates endpoint now gets a load test against a mocked supplier API before it goes to production, with pprof capturing CPU and allocation profiles. We optimise what the profile shows, not what we think will be slow. This sounds obvious, and it is. We still had to learn it.
What we got right
One decision paid off within weeks of the first supplier going live: end-to-end metrics, tagged with the supplier, the operation, and the response shape. When something gets slow or starts returning errors, the dashboard tells us which supplier and which operation, rather than simply saying that ‘SupplierHub is degraded’. The HTTP client lesson above would have been much more difficult to diagnose without it.
What this is really about
We did not go ‘back to the monolith’. CRG is still a distributed system across many bounded contexts and will stay that way. What we did was notice that one of those contexts had been over-decomposed for its current workload, and right-sized it.
If there is a takeaway for engineers reading this, it is that architectural shape is not a fashion choice. The trade-offs that justified service-per-supplier in 2017 were real. Around the time we hit 50 services, they no longer held. Those trade-offs may change again in a few years, and if they do, we will move again.
The thing we try to optimise for is being honest about what the system actually needs now, and being willing to change our minds when those needs change.
By Kaspar Soer, Lead Architect at Car Rental Gateway.




